It is more recommended way to use SDK export template class sly.app.Export to create custom export app (we learned it in the previous tutorial - ). However, if your use case is not covered by our export template, you can create your own app from scratch without the template.
We will go through the following steps:
Set up the working environment.
How to write an export script.
How to debug export app.
Advanced debug.
How to run it in Supervisely.
Everything you need to reproduce : source code and additional app files.
Overview of the simple (illustrative) example we will use in tutorial
In this tutorial, we will create a custom export app that exports data from Supervisely into a .tar archive. See the overview of this example
Step 0. Set up the working environment
Before we begin, please clone this repository and set up the working environment - .
Step 1. How to write an export script
Step 1. Import libraries
import json, os
import supervisely as sly
from dotenv import load_dotenv
from tqdm import tqdm
Step 2. Load environment variables
Load ENV variables for debug, has no effect in production
STORAGE_DIR = sly.app.get_data_dir() # path to directory for temp files and result archive
PROJECT_DIR = os.path.join(STORAGE_DIR, str(PROJECT_ID)) # project directory path
sly.io.fs.mkdir(PROJECT_DIR, True)
ANN_FILE_NAME = "labels.json"
app = sly.Application() # run app
# get project info from server
project_info = api.project.get_info_by_id(id=PROJECT_ID)
if project_info is None:
raise ValueError(
f"Project with ID: '{PROJECT_ID}' either doesn't exist, archived or you don't have access to it"
)
sly.logger.info(
f"Exporting Project: id={project_info.id}, name={project_info.name}, type={project_info.type}",
)
meta_json = api.project.get_meta(id=PROJECT_ID)
project_meta = sly.ProjectMeta.from_json(meta_json)
# Check if the app runs from the context menu of the dataset.
if DATASET_ID is not None:
# If so, get the dataset info from the server.
dataset_infos = [api.dataset.get_info_by_id(DATASET_ID)]
if dataset_infos is None:
raise ValueError(
f"Dataset with ID: '{DATASET_ID}' either doesn't exist, archived or you don't have access to it"
)
sly.logger.info(f"Exporting Dataset: id={dataset_infos[0].id}, name={dataset_infos[0].name}")
else:
# If it does not, obtain all datasets infos from the current project.
dataset_infos = api.dataset.get_list(PROJECT_ID)
sly.logger.info(f"Exporting all datasets from project.")
# track progress datasets processing using Tqdm
with tqdm(total=len(dataset_infos)) as ds_pbar:
# iterate over datasets in project
for dataset in dataset_infos:
result_anns = {}
# get dataset images info
images_infos = api.image.get_list(dataset.id)
# track progress using Tqdm
with tqdm(total=dataset.items_count) as pbar:
# iterate over images in dataset
for image_info in images_infos:
labels = []
# create path for each image and download it from server
image_path = os.path.join(PROJECT_DIR, dataset.name, image_info.name)
api.image.download(image_info.id, image_path)
# download annotation for current image
ann_json = api.annotation.download_json(image_info.id)
ann = sly.Annotation.from_json(ann_json, project_meta)
# iterate over labels in current annotation
for label in ann.labels:
# get obj class name
name = label.obj_class.name
# get bounding box coordinates for label
bbox = label.geometry.to_bbox()
labels.append(
{
"class_name": name,
"coordinates": [
bbox.top,
bbox.left,
bbox.bottom,
bbox.right,
],
}
)
result_anns[image_info.name] = labels
# increment the current images progress counter by 1
pbar.update(1)
# increment the current dataset progress counter by 1
ds_pbar.update(1)
# create JSON annotation in new format
filename = os.path.join(PROJECT_DIR, dataset.name, ANN_FILE_NAME)
with open(filename, "w") as file:
json.dump(result_anns, file, indent=2)
# prepare archive from result project dir
archive_path = f"{PROJECT_DIR}.tar"
sly.fs.archive_directory(PROJECT_DIR, archive_path)
sly.fs.remove_dir(PROJECT_DIR)
PROJECT_DIR = archive_path
# upload project to Supervsiely in production mode
if IS_PRODUCTION:
progress = tqdm(
desc=f"Uploading '{os.path.basename(PROJECT_DIR)}'",
total=sly.fs.get_directory_size(PROJECT_DIR),
unit="B",
unit_scale=True,
)
remote_path = os.path.join(
sly.team_files.RECOMMENDED_EXPORT_PATH,
"Supervisely App",
str(TASK_ID),
f"{sly.fs.get_file_name_with_ext(PROJECT_DIR)}",
)
file_info = api.file.upload(
team_id=TEAM_ID,
src=PROJECT_DIR,
dst=remote_path,
progress_cb=progress,
)
api.task.set_output_archive(
task_id=TASK_ID, file_id=file_info.id, file_name=file_info.name
)
sly.logger.info(f"Remote file: id={file_info.id}, name={file_info.name}")
sly.fs.silent_remove(PROJECT_DIR) # remove local directory
app.shutdown() # stop app
Step 2. How to debug export app
In this tutorial, we will be using the Run & Debug section of the VSCode to debug our export app.
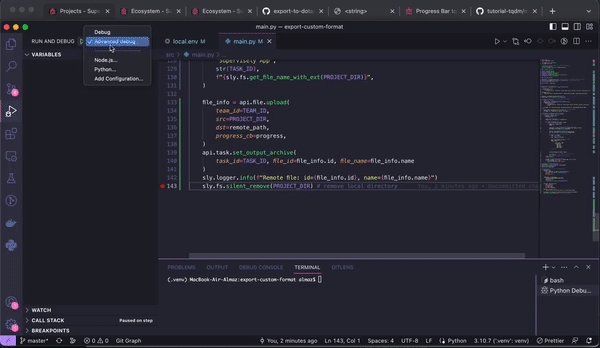
The export template has 2 launch options for debugging: Debug and Advanced Debug. The settings for these options are configured in the launch.json file. Lets start from oprion #1 - Debug
This option is a good starting point. In this case, the resulting archive or folder with the exported data will remain on your computer and be saved in the path that we defined in the local.env file (SLY_APP_DATA_DIR="results/").
In addition to the regular debug option, this template also includes setting for Advanced debugging.
The advanced debugging option is somewhat identical, however it will upload result archive or folder with data to Team Files instead (Path to result archive - /tmp/supervisely/export/Supervisely App/<SESSION ID>/<PROJECT_ID>_<PROJECT_NAME>.tar). This option is an example of how production apps work in Supervisely platform.
Submitting an app to the Supervisely Ecosystem isn’t as simple as pushing code to github repository, but it’s not as complicated as you may think of it either.
Find source code for this example
launch.json
Debug
launch.json
Advanced debug
Please follow this for instructions on adding your app. We have produced a step-by-step guide on how to add your application to the Supervisely Ecosystem.