Sometimes it is needed to organize custom data processing pipeline with using neural networks. This quide illustrates how to import image, process it with detection model and separate predictions with high and low confidences.
neural network pipelines in Supervisely
In this tutorial, you'll learn how to infer deployed models from your code with the sly.nn.inference.Session class and process the images. This class is a convenient wrapper for a low-level API. It under the hood is just a communication with the serving app via requests.
The entire integration Python script takes only 👍 95 lines of code (including comments) and can be found in GitHub repository for this tutorial.
git clone https://github.com/supervisely-ecosystem/example-inference-session
cd example-inference-session
./create_venv.sh
Step 3. Open repository directory in Visual Studio Code.
code -r .
Step 4. change ✅ workspace ID ✅ in local.env file by copying the ID from the context menu of the workspace. A new project with annotated images will be created in the workspace you define. Learn more here.
WORKSPACE_ID=680 # ⬅️ change value
Step 5. Start debugging src/main.py
Python Code
Import libraries
import os
import supervisely as sly
from dotenv import load_dotenv
Init API client
Init api for communicating with Supervisely Instance. First, we load environment variables with credentials and workspace ID:
load_dotenv("local.env")
load_dotenv(os.path.expanduser("~/supervisely.env"))
api = sly.Api()
With next lines we will check the you did everything right - API client initialized with correct credentials and you defined the correct workspace ID in local.env.
workspace_id = sly.env.workspace_id()
workspace = api.workspace.get_info_by_id(workspace_id)
if workspace is None:
print("you should put correct workspaceId value to local.env")
raise ValueError(f"Workspace with id={workspace_id} not found")
Initialize sly.nn.inference.Session
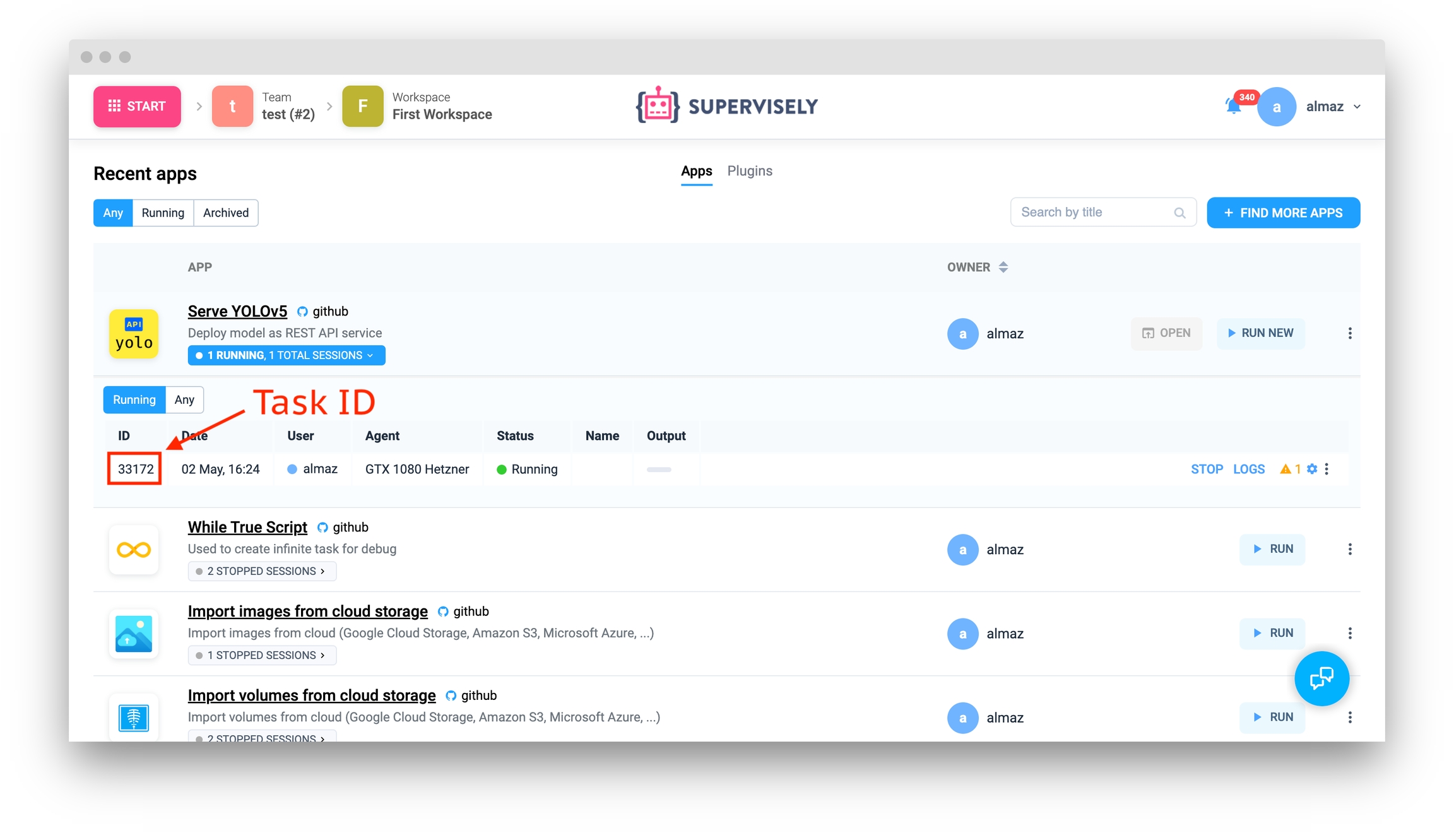
First serve the model you want (e.g. Serve YOLOv5) and copy the task_id from the App sessions section in the Supervisely platform:
Create an Inference Session, a connection to the model:
# Get your Serving App's task_id from the Supervisely platform
task_id = 33172
# Create session
session = sly.nn.inference.Session(api, task_id=task_id)
Create project
Create empty project with name "Model predictions" with one dataset "Week # 1" in your workspace on server. If the project with the same name exists in your dataset, it will be automatically renamed (Week # 1_001, Week # 1_002, etc ...) to avoid name collisions.
project_info = api.project.create(workspace_id, "Model predictions", change_name_if_conflict=True)
dataset_info = api.dataset.create(project_info.id, "Week # 1")
print(f"Project has been sucessfully created, id={project_info.id}")
# Output: Project has been sucessfully created, id=20924
Create 2 new tags: "high confidence" and "need validation"
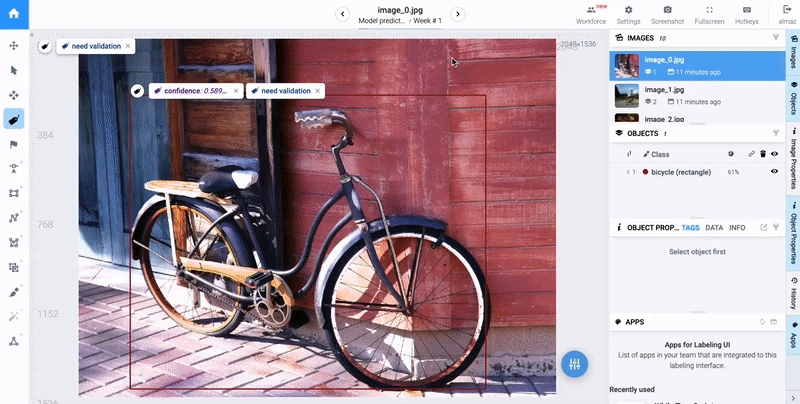
It this section we will make predictions on images and applies tags based on the prediction confidence. If the confidence of the current label is below 0.8, both the label and the current image will be tagged as "need validation," otherwise, the image will be tagged as "high confidence."
By setting tags based on the prediction confidence level, this script enables the separation of the dataset into "high confidence" and "need validation" images. This allows for efficient and automated image processing. ✅
CONFIDENCE_THRESHOLD = 0.8
for i, link in enumerate(links):
# Upload current image from given link to Supervisely server
image_info = api.image.upload_link(dataset_info.id, f"image_{i}.jpg", link)
print(f"Image successfully uploaded, id={image_info.id}")
# Get image inference
prediction = session.inference_image_url(link)
# Check confidence of predictions and set relevant tags.
# If the prediction confidence is lower than the defined threshold,
# both the image and the current label will be marked with the 'need validation' tag.
image_need_validation = False
new_labels = []
for label in prediction.labels:
# Skip the label if object class name is not in list of target class names.
if label.obj_class.name not in target_class_names:
continue
confidence_tag = label.tags.get("confidence")
if confidence_tag.value < CONFIDENCE_THRESHOLD:
new_label = label.add_tag(need_validation_tag)
image_need_validation = True
new_labels.append(new_label)
else:
new_labels.append(label)
prediction = prediction.clone(labels=new_labels)
if image_need_validation is False:
prediction = prediction.add_tag(high_confidence_tag)
else:
prediction = prediction.add_tag(need_validation_tag)
api.annotation.upload_ann(image_info.id, prediction) # Upload annotations to server