In this tutorial you will learn how to integrate custom interactive image matting model into Supervisely Ecosystem. Supervisely Python SDK allows to easily integrate models for numerous image processing tasks. This tutorial takes image matting model (to be more precise, it is a combination of several models united into a single pipeline) as an example and provides a complete instruction to integrate it as an application into Supervisely Ecosystem. You can find and try Matte Anything Supervisely integration . The code for integration can be found .
Implementation details
To integrate your custom video object segmentation model, you need to subclass sly.nn.inference.PromptableSegmentation and implement 4 main methods:
initialize_custom_gui method for building custom GUI for your model;
get_params_from_gui method for getting necessary parameters for model deployment from GUI;
load_model method for loading model on device (CPU / GPU);
serve for serving model as REST API on Supervisely platform - it means that other applications are able to send requests to your model and get predictions from it.
Overall structure
The overall structure of the class we will implement looks like this:
import supervisely as sly
from supervisely.app.widgets import *
from fastapi import Response, Request
class MyModel(sly.nn.inference.PromptableSegmentation):
def initialize_custom_gui(self):
# build custom UI from supervisely widgets, put them into Container and return it
custom_gui = Container(
widgets=list_of_widgets,
)
return custom_gui
def get_params_from_gui(self):
# extract parameters which will be used in load_model method from GUI and return them as a dictionary
return deploy_params
def load_model(self):
# initialize model architecture, load weights and put model on device
pass
def serve(self):
super().serve()
server = self._app.get_server()
@server.post("/smart_segmentation")
def smart_segmentation(response: Response, request: Request):
pass
model = MyModel()
model.serve()
As you can see from the code snippet above, it will be necessary to add smart_segmentation endpoint in serve method - it is necessary to enable model to take requests on segmentation from Supervisely image labeling tool.
Matte Anything interactive image matting model
Now let's implement the class specifically for Matte Anything.
Installing necessary packages
Here is a Dockerfile for Serve Matte Anything app development:
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && apt install python3-pip -y
RUN apt-get install -y git
ARG USE_CUDA=0
ENV DEBIAN_FRONTEND=noninteractive
ENV AM_I_DOCKER True
ENV BUILD_WITH_CUDA "${USE_CUDA}"
ENV TORCH_CUDA_ARCH_LIST "8.9"
ENV CUDA_HOME /usr/local/cuda-11.8
RUN pip3 install networkx==2.8.8
RUN pip3 install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu118
RUN apt-get install ffmpeg libgeos-dev libsm6 libxext6 libexiv2-dev libxrender-dev libboost-all-dev -y
RUN git clone https://github.com/hustvl/Matte-Anything.git
RUN pip3 install git+https://github.com/facebookresearch/segment-anything.git
RUN python3 -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
WORKDIR ./Matte-Anything
RUN git clone https://github.com/IDEA-Research/GroundingDINO.git
RUN python3 -m pip install --no-cache-dir wheel
RUN python3 -m pip install --no-cache-dir --no-build-isolation -e GroundingDINO
RUN pip3 install opencv-python==4.8.0.74
RUN pip3 install gradio==3.41.2
RUN pip3 install fairscale
RUN python3 -m pip install supervisely==6.73.82
RUN pip3 install urllib3==1.26.17
RUN pip3 install einops==0.8.0
RUN apt-get -y install curl
RUN apt -y install wireguard iproute2
RUN apt-get -y install wget
RUN apt-get install nano
Downloading weights of models
Preparing json files with models data
We will need to create a json file for each model group - this data will be used to create model tables in UI and load models in code.
Here are json files for Segment Anything, Grounding DINO and ViTMatte respectively:
We will put these files into models_data directory.
Step-by-step class implementation
Defining imports and global variables
import os
import cv2
import torch
import numpy as np
from PIL import Image
from torchvision.ops import box_convert
from torchvision.transforms import functional as F
from detectron2.config import LazyConfig, instantiate
from detectron2.checkpoint import DetectionCheckpointer
from segment_anything import sam_model_registry, SamPredictor
import groundingdino.datasets.transforms as T
from groundingdino.util.inference import (
load_model as dino_load_model,
predict as dino_predict,
)
import supervisely as sly
from typing import Literal
from typing import List, Any, Dict
import threading
from cachetools import LRUCache
from cacheout import Cache
from supervisely.sly_logger import logger
from supervisely.nn.inference.interactive_segmentation import functional
from supervisely.app.content import get_data_dir
from supervisely.imaging import image as sly_image
from supervisely._utils import rand_str
from fastapi import Response, Request, status
import time
import base64
from PIL import Image
from dotenv import load_dotenv
from supervisely.app.widgets import (
RadioTable,
Field,
Checkbox,
Input,
InputNumber,
Container,
Empty,
)
load_dotenv("local.env")
load_dotenv("supervisely.env")
is_debug_session = bool(os.environ.get("IS_DEBUG_SESSION", False))
original_dir = os.getcwd()
initialize_custom_gui
def get_models(self):
model_types = ["Segment Anything", "Grounding DINO", "ViTMatte"]
self.models_dict = {}
for model_type in model_types:
if model_type == "Segment Anything":
model_data_path = "./models_data/segment_anything.json"
elif model_type == "Grounding DINO":
model_data_path = "./models_data/grounding_dino.json"
elif model_type == "ViTMatte":
model_data_path = "./models_data/vitmatte.json"
model_data = sly.json.load_json_file(model_data_path)
self.models_dict[model_type] = model_data
return self.models_dict
def initialize_custom_gui(self):
models_data = self.get_models()
def remove_unnecessary_keys(data_dict):
new_dict = data_dict.copy()
new_dict.pop("weights", None)
new_dict.pop("config", None)
return new_dict
sam_model_data = models_data["Segment Anything"]
sam_model_data = [remove_unnecessary_keys(d) for d in sam_model_data]
gr_dino_model_data = models_data["Grounding DINO"]
gr_dino_model_data = [remove_unnecessary_keys(d) for d in gr_dino_model_data]
vitmatte_model_data = models_data["ViTMatte"]
vitmatte_model_data = [remove_unnecessary_keys(d) for d in vitmatte_model_data]
self.sam_table = RadioTable(
columns=list(sam_model_data[0].keys()),
rows=[list(element.values()) for element in sam_model_data],
)
self.sam_table.select_row(2)
sam_table_f = Field(
content=self.sam_table,
title="Pretrained Segment Anything models",
)
self.vitmatte_table = RadioTable(
columns=list(vitmatte_model_data[0].keys()),
rows=[list(element.values()) for element in vitmatte_model_data],
)
self.vitmatte_table.select_row(3)
vitmatte_table_f = Field(
content=self.vitmatte_table,
title="Pretrained ViTMatte models",
)
self.erode_input = InputNumber(value=20, min=1, max=30, step=1)
erode_input_f = Field(
content=self.erode_input,
title="Erode kernel size",
)
self.dilate_input = InputNumber(value=20, min=1, max=30, step=1)
dilate_input_f = Field(
content=self.dilate_input,
title="Dilate kernel size",
)
erode_dilate_inputs = Container(
widgets=[erode_input_f, dilate_input_f, Empty()],
direction="horizontal",
fractions=[1, 1, 2],
)
self.gr_dino_checkbox = Checkbox(content="use Grounding DINO", checked=False)
gr_dino_checkbox_f = Field(
content=self.gr_dino_checkbox,
title="Choose whether to use Grounding DINO or not",
description=(
"If selected, then Grounding DINO will be used to detect transparent objects on images "
"and correct trimap based on detected objects"
),
)
self.gr_dino_table = RadioTable(
columns=list(gr_dino_model_data[0].keys()),
rows=[list(element.values()) for element in gr_dino_model_data],
)
gr_dino_table_f = Field(
content=self.gr_dino_table,
title="Pretrained Grounding DINO models",
)
gr_dino_table_f.hide()
self.dino_text_prompt = Input(
"glass, lens, crystal, diamond, bubble, bulb, web, grid"
)
self.dino_text_prompt.hide()
dino_text_input_f = Field(
content=self.dino_text_prompt,
title="Text prompt for detecting transparent objects using Grounding DINO",
)
dino_text_input_f.hide()
self.dino_text_thresh_input = InputNumber(
value=0.25, min=0.1, max=0.9, step=0.05
)
dino_text_thresh_input_f = Field(
content=self.dino_text_thresh_input,
title="Grounding DINO text confindence threshold",
)
self.dino_box_thresh_input = InputNumber(value=0.5, min=0.1, max=0.9, step=0.1)
dino_box_thresh_input_f = Field(
content=self.dino_box_thresh_input,
title="Grounding DINO box confindence threshold",
)
dino_thresh_inputs = Container(
widgets=[dino_text_thresh_input_f, dino_box_thresh_input_f, Empty()],
direction="horizontal",
fractions=[1, 1, 2],
)
dino_thresh_inputs.hide()
@self.gr_dino_checkbox.value_changed
def change_dino_ui(value):
if value:
gr_dino_table_f.show()
self.dino_text_prompt.show()
dino_text_input_f.show()
dino_thresh_inputs.show()
else:
gr_dino_table_f.hide()
self.dino_text_prompt.hide()
dino_text_input_f.hide()
dino_thresh_inputs.hide()
custom_gui = Container(
widgets=[
sam_table_f,
vitmatte_table_f,
erode_dilate_inputs,
gr_dino_checkbox_f,
gr_dino_table_f,
dino_text_input_f,
dino_thresh_inputs,
],
gap=25,
)
return custom_gui
As you can see from the code above, there are two functions inside initialize_custom_gui method: remove_unnecessary_keys and change_dino_ui. The first one is used in order to remove config and checkpoint paths from model tables since we do not want this data to be displayed in UI, we will need this data only in our code. The second one is used for interaction witb user: if user chooses to use Grounding DINO, then part of UI with Grounding DINO settings will appear.
load_model
The code below initializes Segment Anything, ViTMatte and (if necessary) Grounding DINO models, loads their checkpoints and puts them on device:
We will also need some additional methods for serving our model on Supervisely platform:
def get_info(self):
info = super().get_info()
info["videos_support"] = False
info["async_video_inference_support"] = False
return info
def get_classes(self) -> List[str]:
return self.class_names
@property
def model_meta(self):
if self._model_meta is None:
self._model_meta = sly.ProjectMeta(
[sly.ObjClass(self.class_names[0], sly.Bitmap, [255, 0, 0])]
)
self._get_confidence_tag_meta()
return self._model_meta
After we have initialized necessary models, we can start implementing serve method. But before doing it, we will have to implement some methods which we will use to process image data and generate trimaps artificially:
Image matting task usually assumes usage of trimap - specific mask which divides input image into three types of areas: foreground, background, and transition region. But manual creation of trimap can be very time-consuming. Matte Anything uses segmentation mask predicted by Segment Anything and processes it via erosion and dilation (in code it is implemented in generate_trimap method) to generate trimap automatically. ViTMatte uses this trimap as an input to predict alpha mask. If user has chosen to use Grounding DINO, then this model will be used for detecting transparent objects - if such objects were found on image, then trimap will be corrected based on this information - convert_pixels method is used in order to put such objects into transition area of trimap. set_image_data method is used to avoid unnecessary calculations - if given image id is in cache, then it means that predictor features for this image are already calculated and we can simply take them from cache instead of calculating them again from scratch.
serve
The code below implements serve method with smart_segmentation endpoint for taking requests on segmentation and sending responses with encoded mask to the platform:
If you develop in a Docker container, you should run the container with --cap_add=NET_ADMIN option.
Install sudo apt-get install wireguard iproute2 or brew install wireguard-tools for Mac.
Define your TEAM_ID in the debug.env file. *Actually there are other env variables that is needed, but they are already provided in ./vscode/launch.json for you.
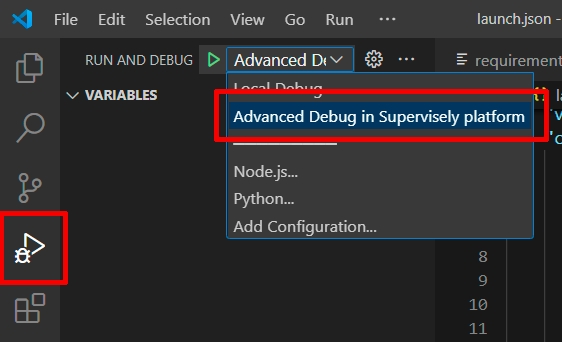
Switch the launch.json config to the Advanced debug in Supervisely platform:
Run the code.
✅ It will deploy the model in the Supervisely platform as a REST API.
Here is how advanced debug mode launch looks like:
After advanced debug launch you must be able to debug your app via Develop & Debug app:
serving_app/README.md - readme of your application, it is the main page of an application in Ecosystem with some images, videos, and how-to-use guides
serving_app/config.json - configuration of the Supervisely application, which defines the name and description of the app, its context menu, icon, poster, and running settings
supervisely.env - file with variables used for debugging
docker/ - directory with the custom Dockerfile for this application and the script that builds it and publishes it to the docker registry
type - type of the module in Supervisely Ecosystem
version - version of Supervisely App Engine. Just keep it by default
name - the name of the application
description - the description of the application
categories - these tags are used to place the application in the correct category in Ecosystem
session_tags - these tags will be assigned to every running session of the application. They can be used by other apps to find and filter all running sessions
need_gpu: true - should be true if you want to use any cuda devices
gpu: required - app can be runned only on GPU devices
community_agent: false - this means that this app can not be run on the agents started by Supervisely team, so users have to connect their own computers and run the app only on their own agents. Only applicable in Community Edition. Enterprise customers use their private instances so they can ignore the current option
docker_image - Docker container will be started from the defined Docker image, github repository will be downloaded and mounted inside the container
entrypoint - the command that starts our application in a container
port - port inside the container
App release
Once you've tested the code, it's time to release it into the platform. It can be released as an App that is shared with the all Supervisely community, or as your own private App.
We recommend to develop apps using VS Code extension - it will simplify installation of necessary packages.
After installing all necessary packages, it will be also necessary to download weights of models (Matte Anything uses , and ) and put them into pretrained folder. Here are the links for , and pretrained checkpoints. For local debug we can load model weights from local storage, but in production we recommend to save weights to a Docker image.
The following code builds custom GUI from Supervisely (we will also need get_models method in order to read json files with models data and preprocess extracted data):
You can read more about advanced debug mode .
Advanced Debug in Supervisely
The structure of is the following:
App configuration is stored in config.json file. A detailed explanation of all possible fields is covered in this . Let's check the config for our current app:
Refer to for all releasing details. For a private app check also .