Instance segmentation
Step-by-step tutorial of how to integrate custom instance segmentation neural network into Supervisely platform on the example of detectron2.
Last updated
Was this helpful?
Step-by-step tutorial of how to integrate custom instance segmentation neural network into Supervisely platform on the example of detectron2.
Last updated
Was this helpful?
In this tutorial you will learn how to integrate your custom instance segmentation model into Supervisely by creating a simple serving app. As an example, we will use repository, which implements a set of detection models.
Step 1. Prepare ~/supervisely.env file with credentials.
Step 2. Clone with source code and create .
Step 3. Open the repository directory in Visual Studio Code.
Step 4. Run debug for script src/main.py
The integration script is simple:
Automatically downloads NN weights to ./my_model folder
Loads model on the CPU or GPU device
Runs inference on a demo image
Visualizes predictions on top of the input image
To integrate your model, you need to subclass sly.nn.inference.InstanceSegmentation and implement 3 methods:
load_on_device method for downloading the weights and initializing the model on a specific device. Takes a model_dir argument, that is a directory for all model files (like configs, weights, etc). The second argument is a device - a torch.device like cuda:0, cpu.
get_classes method should return a list of class names (strings) that model can predict.
predict. The core implementation of a model inference. It takes a path to an image and inference settings as arguments, applies the model inference to the image and returns a list of predictions (which are sly.nn.PredictionMask objects).
The overall structure of the class we will implement is looking like this:
The superclass has a serve() method. For running the code on the Supervisely platform, m.serve() method should be executed:
And here is the beauty comes in. The method serve() internally handles everything and deploys your model as a REST API service on the Supervisely platform. It means that other applications are able to communicate with your model and get predictions from it.
So let's implement the class.
Defining imports and global variables
1. load_on_device
The following code downloads model weights, creates the model according to config my_model/model_info.json (which will instantiate one of detectron2 architecture). Also it will keep the model as a self.predictor and classes as self.class_names for further use:
2. get_classes
Simply returns previously saved class_names:
3. predict
The core method for model inference. Here we are reading an image and getting an inference of the model. The code here is usually borrowed from the framework or the model you use, that is detectron2 in our case. It let us simply use self.predictor(image). Then we wrap model predictions into sly.nn.PredictionMask and do some post-processing steps.
It must return exactly a list of sly.nn.PredictionMask objects for compatibility with Supervisely. Your code should just wrap the prediction: sly.nn.PredictionMask(class_name, mask, score), where the mask is a np.array prediction mask and the score is a float confidence_score.
Usage of our class
Once the class is created, here we initialize it and get one test prediction for debugging.
Here are the input image and output predictions:
The beauty of this class is that you can easily debug your code locally in your favorite IDE.
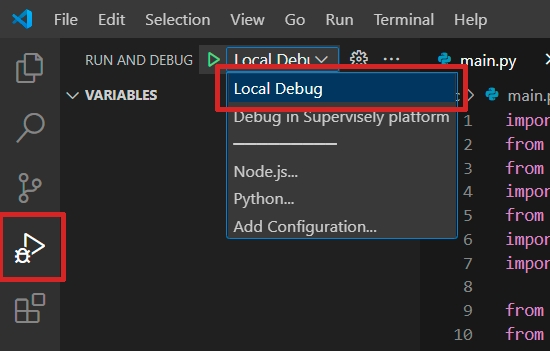
You can run the code locally for debugging. For Visual Studio Code we've created a launch.json config file that can be selected:
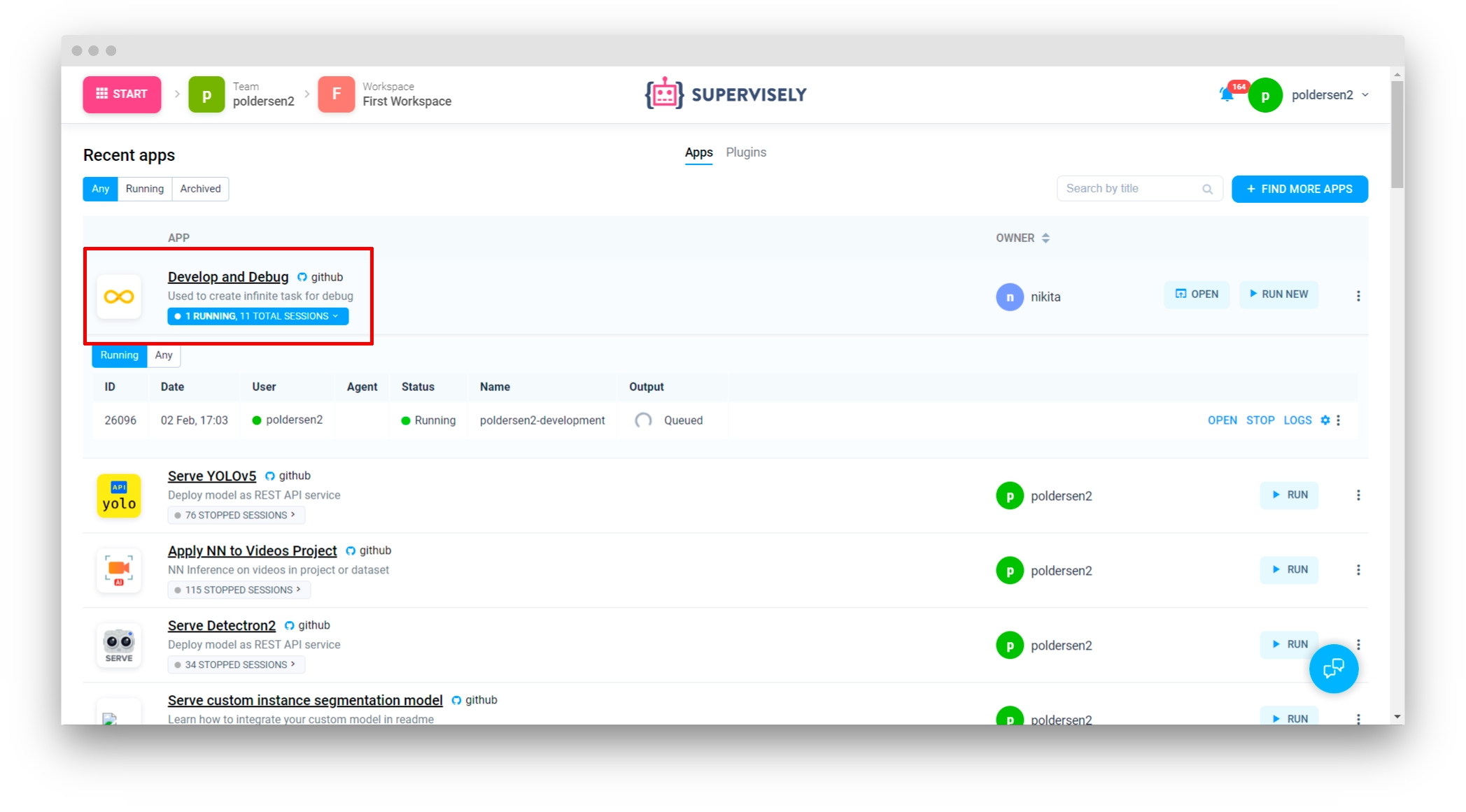
Once the code seems working locally, it's time to test the code right in the Supervisely platform as a debugging app. For that:
If you develop in a Docker container, you should run the container with --cap_add=NET_ADMIN option.
Install sudo apt-get install wireguard iproute2.
Define your TEAM_ID in the local.env file. Actually there are other env variables that is needed, but they are already provided in ./vscode/launch.json for you.
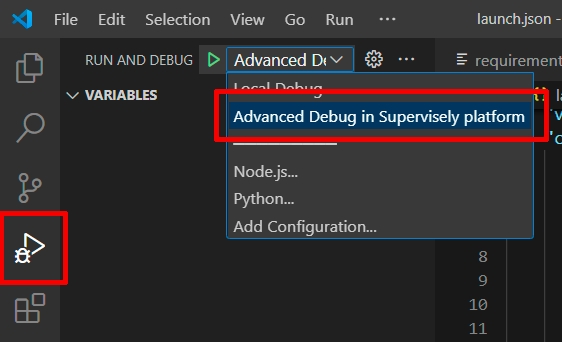
Switch the launch.json config to the Advanced debug in Supervisely platform:
Run the code.
✅ It will deploy the model in the Supervisely platform as a regular serving App that is able to communicate with all others app in the platform:
Once you've tested the code, it's time to release it into the platform. It can be released as an App that shared with the all Supervisely community, or as your own private App.
In this tutorial we'll quickly observe the key concepts of our app.
Explanation:
src/main.py - main inference script
my_model - directory with model weights and additional config files
demo_data - directory with demo image for inference
README.md - readme of your application, it is the main page of an application in Ecosystem with some images, videos, and how-to-use guides
config.json - configuration of the Supervisely application, which defines the name and description of the app, its context menu, icon, poster, and running settings
create_venv.sh - creates a virtual environment, installs detectron2 framework, includes the support of Apple CPUs (m1 / m2 ...)
requirements.txt - all packages needed for debugging
local.env - file with variables used for debugging
docker - directory with the custom Dockerfile for this application and the script that builds it and publishes it to the docker registry
Here is the explanation for the fields:
type - type of the module in Supervisely Ecosystem
version - version of Supervisely App Engine. Just keep it by default
name - the name of the application
description - the description of the application
categories - these tags are used to place the application in the correct category in Ecosystem.
session_tags - these tags will be assigned to every running session of the application. They can be used by other apps to find and filter all running sessions
"need_gpu": true - should be true if you want to use any cuda devices.
"community_agent": false - this means that this app can not be run on the agents started by Supervisely team, so users have to connect their own computers and run the app only on their own agents. Only applicable in Community Edition. Enterprise customers use their private instances so they can ignore current option
docker_image - Docker container will be started from the defined Docker image, github repository will be downloaded and mounted inside the container.
entrypoint - the command that starts our application in a container
port - port inside the container
"headless": true means that the app has no User Interface
The entire integration Python script takes only 👍 90 lines of code (including comments) and can be found in for this tutorial.
In the code below a custom_inference_settings is used. It allows us to provide a custom settings that could be used in predict() (See more in )
Now you can use apps like , with your deployed model.
Or get the model inference via Python API with the help of sly.nn.inference.Session class just in one line of code. See .
Refer to for all releasing details. For a private app check also .
The structure of is the following:
App configuration is stored in config.json file. A detailed explanation of all possible fields is covered in this . Let's check the config for our current app: