In this article, we will learn how to iterate through a project with annotated data in python. It is one of the most frequent operations in Superviely Apps and python automation scripts.
Dataset Types
In Supervisely, datasets can be organized in two ways: flat or nested. Understanding these structures can help you with efficient data organization and management.
Flat Dataset Structure
A flat dataset is the simplest form of organization where all images and their annotations are stored in a single level. This structure is good for simple projects with straightforward organization.
You can add this dataset to your team via Supervisely Ecosystem - ⬇️
A nested dataset structure is a bit more advanced. It lets you create datasets inside other datasets, forming a hierarchy—like tree for your data. Nested datasets are good for complex projects requiring hierarchical organization or when you need to group related data together.
Important Note about Nested Datasets:
When working with nested datasets, keep in mind:
Parent datasets (like "Temperate" or "Tropical") can be empty or non-empty themselves, but contain images inside nested datasets
To get all parent dataset images including nested ones, you'll need to iterate through each nested dataset
Example structure:
The main datasets ("Temperate" and "Tropical") don't hold images or annotations directly in ann and img folders.
Instead, they have a datasets folder containing nested datasets (like "Apple", "Banana", etc.), and those hold the images and annotations.
The main datasets can also contain images, but we removed them for this example
In this guide we will go through the following steps:
1. Demo project
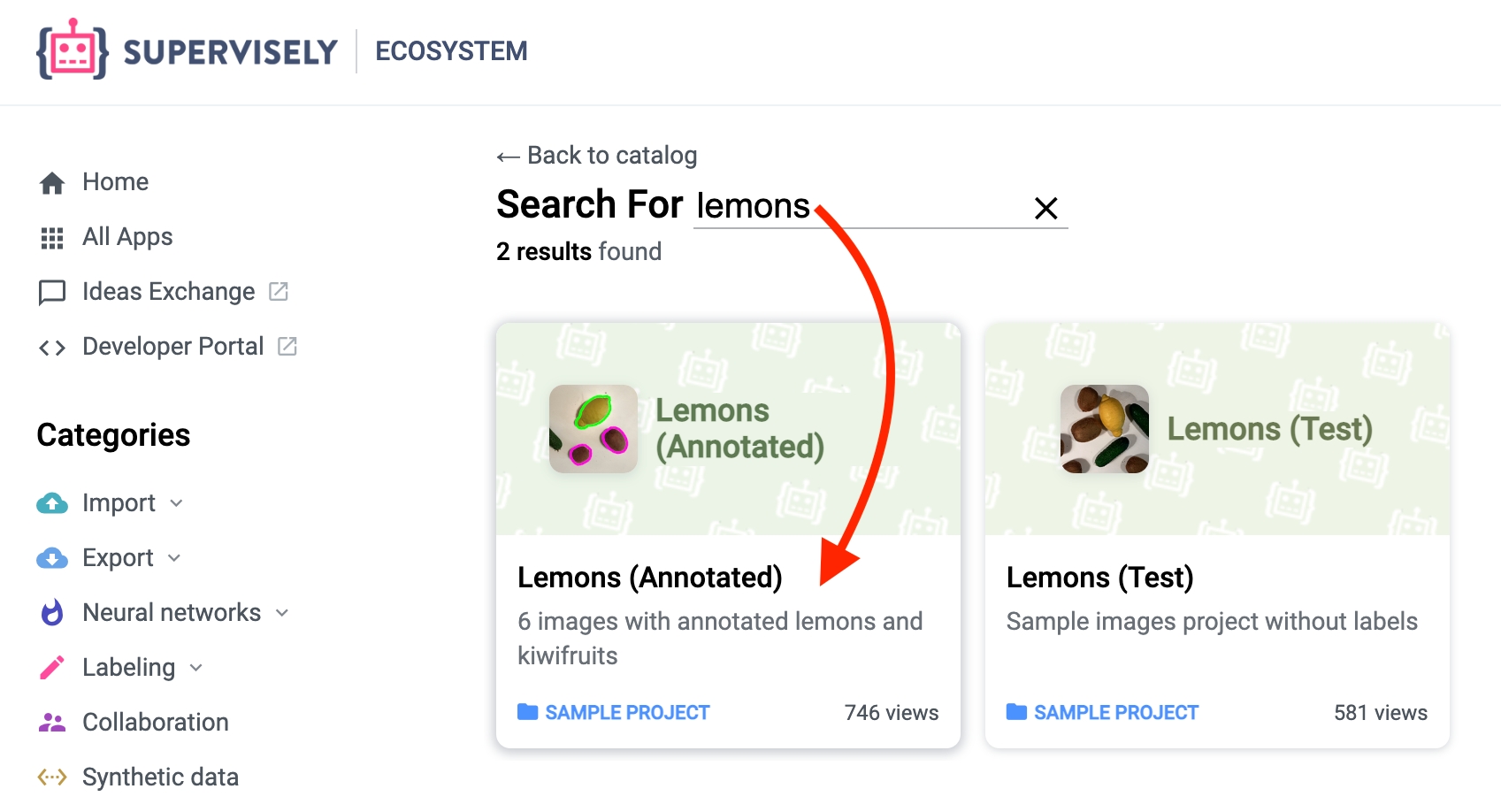
If you don't have any projects yet, go to the ecosystem and add the demo project 🍋 Lemons (Annotated) or 🍍 Fruits Nested (Annotated) to your current workspace.
2. .env files
# your API credentials, learn more here: https://developer.supervisely.com/getting-started/basics-of-authentication
SERVER_ADDRESS="https://app.supervisely.com" # ⬅️ change it if use Enterprise Edition
API_TOKEN="4r47N.....blablabla......xaTatb" # ⬅️ change it
Create the second file local.env and place it in the same directory with the main.py. This file will contain values we are going to use in the python script.
# change the Project ID to your value
PROJECT_ID=12208 # ⬅️ change it
3. Python script
To start debugging you need to
Check that you have ~/supervisely.env file with correct values
Source code
import os
import supervisely as sly
from dotenv import load_dotenv
if sly.is_development():
load_dotenv("local.env")
load_dotenv(os.path.expanduser("~/supervisely.env"))
api = sly.Api.from_env()
project_id = sly.env.project_id()
project = api.project.get_info_by_id(project_id)
if project is None:
raise KeyError(f"Project with ID {project_id} not found in your account")
print(f"Project info: {project.name} (id={project.id})")
# get project meta - collection of annotation classes and tags
meta_json = api.project.get_meta(project.id)
project_meta = sly.ProjectMeta.from_json(meta_json)
print(project_meta)
# Set recursive to True if you want to include nested datasets
datasets = api.dataset.get_list(project.id, recursive=True)
print(f"There are {len(datasets)} datasets in project")
for dataset in datasets:
print(f"Dataset {dataset.name} has {dataset.items_count} images")
images = api.image.get_list(dataset.id)
for image in images:
ann_json = api.annotation.download_json(image.id)
ann = sly.Annotation.from_json(ann_json, project_meta)
print(f"There are {len(ann.labels)} objects on image {image.name}")
If you are working with nested datasets and want to get full path to the dataset, you can use api.dataset.tree method instead of api.dataset.get_list.
It returns a generator that yields tuples (parents, dataset) where parents is a list of parent dataset names and dataset is a dataset object.
Your for loop will look like this:
for parents, dataset in api.dataset.tree(project_id):
print(f"Dataset path: {'/'.join(parents + [dataset.name])}")
print(f"Dataset {dataset.name} has {dataset.items_count} images")
images = api.image.get_list(dataset.id)
for image in images:
ann_json = api.annotation.download_json(image.id)
ann = sly.Annotation.from_json(ann_json, project_meta)
print(f"There are {len(ann.labels)} objects on image {image.name}")
# >>> Dataset path: Temperate
# >>> Dataset Temperate has 0 images
# >>>
# >>> Dataset path: Temperate/Apple
# >>> Dataset Apple has 3 images
# >>> There are 1 objects on image apple_2.jpg
# >>> There are 1 objects on image apple_1.jpg
# >>> There are 1 objects on image apple_3.jpg
# >>>
# >>> Dataset path: Temperate/Pear
# >>> Dataset Pear has 3 images
# >>> There are 1 objects on image pear_3.jpg
# >>> There are 1 objects on image pear_1.jpg
# >>> There are 1 objects on image pear_2.jpg
# >>> ...
Output
The script above produces the following output for Lemons (Annotated) project:
Project info: Lemons (Annotated) (id=12208)
ProjectMeta:
Object Classes
+-------+--------+----------------+--------+
| Name | Shape | Color | Hotkey |
+-------+--------+----------------+--------+
| kiwi | Bitmap | [255, 0, 0] | |
| lemon | Bitmap | [81, 198, 170] | |
+-------+--------+----------------+--------+
Tags
+------+------------+-----------------+--------+---------------+--------------------+
| Name | Value type | Possible values | Hotkey | Applicable to | Applicable classes |
+------+------------+-----------------+--------+---------------+--------------------+
+------+------------+-----------------+--------+---------------+--------------------+
There are 1 datasets in project
Dataset ds1 has 6 images
There are 3 objects on image IMG_1836.jpeg
There are 4 objects on image IMG_8144.jpeg
There are 4 objects on image IMG_3861.jpeg
There are 3 objects on image IMG_0748.jpeg
There are 5 objects on image IMG_4451.jpeg
There are 7 objects on image IMG_2084.jpeg
The script above produces the following output for Fruits Nested (Annotated) project:
Project info: Fruits Nested (Annotated) (id=1317)
ProjectMeta:
Object Classes
+-----------+-----------+----------------+--------+
| Name | Shape | Color | Hotkey |
+-----------+-----------+----------------+--------+
| Lemon | Rectangle | [144, 19, 254] | |
| Apple | Rectangle | [208, 2, 27] | |
| Pineapple | Rectangle | [248, 231, 28] | |
| Pear | Rectangle | [126, 211, 33] | |
| Orange | Rectangle | [80, 227, 194] | |
| Banana | Rectangle | [139, 87, 42] | |
| Mango | Rectangle | [74, 144, 226] | |
+-----------+-----------+----------------+--------+
Tags
+-----------+------------+-----------------+--------+---------------+--------------------+-------------+
| Name | Value type | Possible values | Hotkey | Applicable to | Applicable classes | Target type |
+-----------+------------+-----------------+--------+---------------+--------------------+-------------+
| Apple | none | None | | all | [] | all |
| Banana | none | None | | all | [] | all |
| Lemon | none | None | | all | [] | all |
| Mango | none | None | | all | [] | all |
| Orange | none | None | | all | [] | all |
| Pear | none | None | | all | [] | all |
| Pineapple | none | None | | all | [] | all |
+-----------+------------+-----------------+--------+---------------+--------------------+-------------+
There are 9 datasets in project
Dataset Temperate has 0 images
Dataset Apple has 3 images
There are 1 objects on image apple_2.jpg
There are 1 objects on image apple_1.jpg
There are 1 objects on image apple_3.jpg
Dataset Pear has 3 images
There are 1 objects on image pear_3.jpg
There are 1 objects on image pear_1.jpg
There are 1 objects on image pear_2.jpg
Dataset Tropical has 0 images
Dataset Banana has 3 images
There are 1 objects on image banana_1.jpg
There are 1 objects on image banana_2.jpg
There are 3 objects on image banana_3.jpg
Dataset Mango has 4 images
There are 1 objects on image mango_3.jpg
There are 1 objects on image mango_1.jpg
There are 1 objects on image mango_4.jpg
There are 1 objects on image mango_2.jpg
Dataset Pineapple has 3 images
There are 1 objects on image pineapple_3.jpg
There are 1 objects on image pineapple_2.jpg
There are 1 objects on image pineapple_1.jpg
Dataset Lemon has 3 images
There are 1 objects on image lemon_1.jpg
There are 1 objects on image lemon_3.jpg
There are 1 objects on image lemon_2.jpg
Dataset Orange has 3 images
There are 1 objects on image orange_2.jpg
There are 1 objects on image orange_1.jpg
There are 1 objects on image orange_3.jpg
4. Optimizations
The bottleneck of this script is in these lines (27-28):
for image in images:
ann_json = api.annotation.download_json(image.id)
If you have 1M images in your project, your code will send 🟡 1M requests to download annotations. It is inefficient due to Round Trip Time (RTT) and a large number of similar tiny requests to a Supervisely database.
It can be optimized by using the batch API method:
Supervisely API allows downloading annotations for multiple images in a single request. The code sample below sends ✅ 50x fewer requests and it leads to a significant speed-up of our original code:
for batch in sly.batched(images):
image_ids = [image.id for image in batch]
annotations = api.annotation.download_json_batch(dataset.id, image_ids)
for image, ann_json in zip(batch, annotations):
ann = sly.Annotation.from_json(ann_json, project_meta)
print(f"There are {len(ann.labels)} objects on image {image.name}")
You can add this dataset to your team via Supervisely Ecosystem - ⬇️
Everything you need to reproduce : source code, Visual Studio code configuration, and a shell script for creating venv.
**** Get a demo project with labeled or with nested datasets.
**** Prepare .env files with credentials and ID of a demo project.
**** Run .
**** Show possible optimizations.
Add demo project "Lemons (Annotated)" to your workjspace
Create a file at ~/supervisely.env with the credentials for your Supervisely account. Learn more about environment variables . The content should look like this:
This script illustrates only the basics. If your project is huge and has hundreds of thousands of images then it is not so efficient to download annotations one by one. It is better to use batch (bulk) methods to reduce the number of API requests and significantly speed up your code. Learn more in below.
Clone the
Create by running the script
Change value in
The optimized version of the original script is in .